Use of Transfer Learning in Early Pneumonia Detection
16 Feb 2023 - Arisha Prasai
Transfer learning is a technique in machine learning where a pre-trained model is used as a starting point for a new task, rather than training a new model from scratch. It is beneficial for disease detection because it can leverage the features learned from a large dataset to improve the accuracy of smaller datasets, leading to faster and more efficient diagnosis.
Now, let’s apply this concept to detecting diseases like pneumonia. Traditional machine learning models require large datasets to learn from, which can be a challenge in the medical field where data is often scarce or private. But with transfer learning, we can take advantage of pre-trained models that have already learned complex features from huge datasets of images. By fine-tuning these models on smaller datasets of medical images, we can achieve higher accuracy and faster diagnoses.
Why Pneumonia Detection?
- Pneumonia is more common among children below 5 years of age.
-According to the UNICEF report 2019, it causes death of a child in every 39 seconds in Nepal.
-Most deaths due to pneumonia occur among children of poorest households who are affected by the convergence of poor nutrition, poor hygiene and poor immunization rates.
This project is a small example of how a pre-trained model can be used for early disease detection. We will be using VGG-19 which is a popular deep learning architecture that has been widely used in computer vision tasks and for medical imaging. Moreover, VGG19 has been pre-trained on a large dataset of natural images of size 224 * 224 , which allows it to recognize patterns and shapes that are common to many images. This pre-training enables transfer learning, which is especially beneficial for medical imaging tasks where data is limited. And by fine-tuning the pre-trained VGG19 model on a smaller dataset of X-ray images of pneumonic and non-pneumonic patients on Kaggle, it can quickly learn to recognize specific disease patterns and help clinicians diagnose diseases at an earlier stage.
There are many other pre-trained models like VGG-19 including ResNet, DenseNet, Inception, U-Net or even CovidNet. We could have used any one but for the sake of this post, we will be using VGG-19.
Now, lets dive into it.
The dataset can be found here:
https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia
IMPORTING LIBRARIES
Importing the libraries and other dependencies is the first step before dealing with any data . So, we do that in the code below. Also, since it is time consuming to download the whole dataset from Kaggle, we use Kaggle API to avoid that.
Now since every ML model takes numbers as input, we need to find a way to represent each image in form of numbers. So, we create a function to that takes image as input and converts into a matrix of (150,150).Although VGG-19 was trained on input images of (224,224), the reason for creating a (150,150) matrix is because sessions kept on crashing on Google Colab. So there is definite loss of data but hopefully not so much.
NORMALISING THE DATA
Normalizing image data is an important step in preprocessing image data before feeding it into a machine learning model. One reason for normalizing image data is to reduce the effects of lighting and color variations in the input data. This is especially important in medical imaging, where images may have different brightness and contrast levels due to variations in imaging equipment, patient positioning, or lighting conditions.
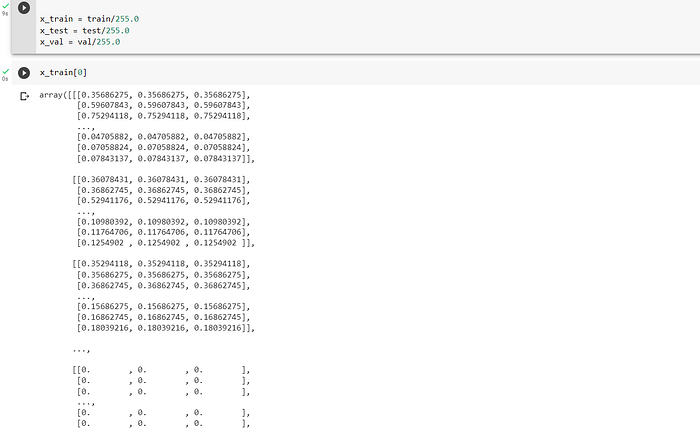
Likewise, another reason for normalizing image data is to prevent numerical instability during model training. Some machine learning algorithms are sensitive to the scale of the input data, and may not perform well if the input values are too large or too small. We do this by dividing by 255.0 of each value in the matrix because the pixels range from 0–255. This will make all values to align to the same scale of rane 0–1 like shown in the code snippet below:
DEFINING TARGET VARIABLES
Next, we define target variables and apply image augmentation technique. Image augmentation is used to increase the size of the training dataset, improve model generalization, reduce overfitting, introduce noise, and increase model robustness to image variations and distortions by zooming, altering the orientations, adding filler values and so on.
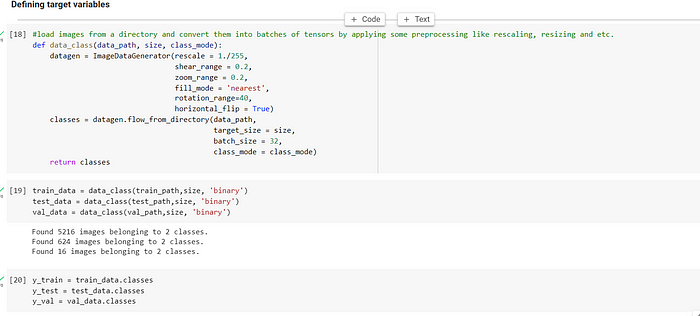

In the code above, we use flow_from_directory and ImageDataGenerator class in Keras that saves input data in the form of NumPy arrays, which are a commonly used data structure in Python for numerical computing.
COMPILING THE VGG-19 MODEL
Since we are using a pre-trained model, its is necessary to NOT TRAIN the weights of the first 19 layers . Then, we flatten the ouput of the model to connect it with other 2 Dense layers. The last Dense layer has only one neuron as this use case is a binary classification i.e. the patient is either pneumonic or normal. We have set sigmoid function as activation that gives probability from 0–1, where having 0.5 or greater value means the model predicted patient to have pneumonia and lesser than 0.5 indicates that the model predicted that the patient doesn’t have pneumonia. In this way, a fully connected neural network is made using pre-trained model.
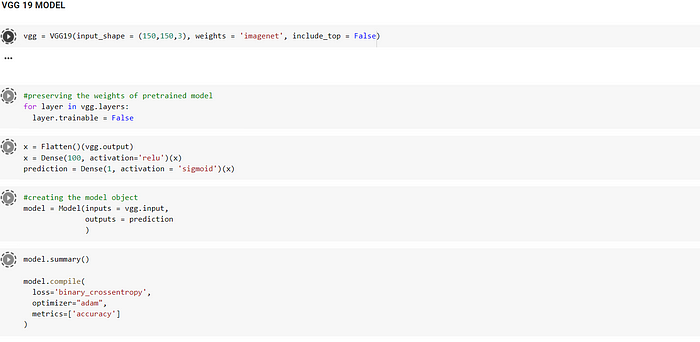
Below is the snippet of the neural networks formed. Notice that the parameters that are trainable are the parameters of the last two Dense layers.


TRAINING THE MODEL ON THE DATA
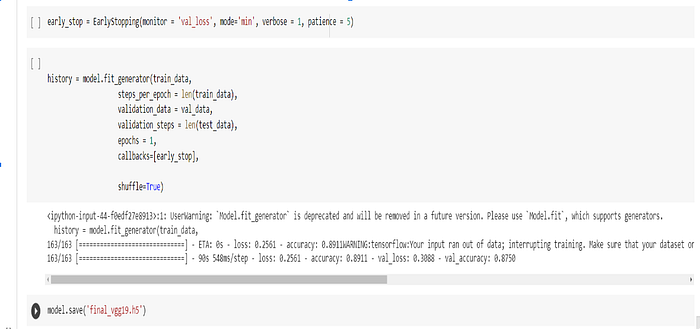
RESULT
Data augmentation has been used as this was an imbalanced dataset to prevent overfitting. The model scored an accuracy of 89% on the training set and 87% on the validation set. The model is still overfitting to some extent.
We then save this model as an h5 file and later into a joblib file which can later be used for direct prediction without having to train again.
DEMO OF THE MODEL
In the demo below, 3/3 images of untrained dataset of pneumonic and normal X-rays were used to predict the result. In this case, the model seemed to have performed well by classifying all of them correctly.
However, the model may still be improved using hyperparameter techniques to prevent overfitting and gradually increasing the accuracy. This can be done by changing the number of layers ,neurons or trying different activation techniques.
In conclusion, transfer learning makes life easier by enabling us to make our own customized model for wide variety of computer vision use cases. Computer aided diagnostics using DL models can assist doctors in early and accurate disease detection, aid human decision making, save time and resources or can even simplify complex procedures. Hence, the use of transfer learning in early disease detection is ample.
Code for Nepal would like to thank DataCamp Donates for providing Arisha, and several other fellows access to DataCamp, to learn and grow.