Data Pipeline with Apache Airflow and Fast API
21 Feb 2023 - Prashant Manandhar
The word Pipeline in general triggers a connections like image in our mind. Well data pipelines are no differ from that. These days organizations/institutions have huge volume of data which are generated through various sources, these data are known as “Big Data”. For processing these big data efficiently such that it saves time and improves results we require data pipeline.Data pipelines are created for ETL process, where data is collected from various sources, it is then transformed into desired format and finally stored.
What is DAG?
DAG stands for Directed Acyclic Graph. In apache airflow DAGs represents a workflow of task that we program in python. According to the task flow that we desire the graph is made.It can be visualized from the UI as well. The priority of task is given by upstream task and downstream task.Task in DAG can be anything i.e request data from API, transforming in desired format, storing data in database and many more.
What is API
API i.e Application Programming Interface is kind of like a messenger. Well when ever we access data using API, its acts as a middle person between the main system and the user.We can understand this by an example. Suppose we need to access data from a system A, scenario is system A donot allow direct access and provides API, when the user send data request to API, API send request to the system A, in similar fashion system A either returns data or error which eventually is received by the user. Besides API requests are not unlimited and general APIs are accesses with the help of API keys for security.
Fast API
Fast API is a framework which can be used to build APIs with the help of python programming language. Fast API is simple ad easy to use. With few lines of code, simple API can be built.We will see the details in the code.
Apache Airflow
For creating data processing pipelines, Apache Airflow is a very useful open source work flow management tool.With the knowledge of python programming language, Airflow can be used to create data processing pipelines. While data from various sources needs to be extracted , transformed and stored, this tool proves to be just perfect.The web UI of Apache airflow is quiet handy while creating a data pipeline.All the DAGs(Direct Acyclic Graphs) that we have created is listed and we can checkout active DAGs and paused DAGs as-well. Individual DAGs can be triggered from the UI as well also we can go through multiple options in UI. There are various operators and sensors that can be used as requirement such as BinaryOperator, PythonOperator, FileSensors etc, Here we will be Using PythonOperator since we require function calling. Also we have op tions for executors in apache airflow i.e Sequential Executor, Local Executor,Celery Executor, where default executor is Sequential Executor.Sequential Executor is only used for testing purpose and executes single task sequentially.
Steps to setup Apache Airflow (in Linux environment)
- open vs code in a new folder
- Makesure the path in “apache.cfg” is exactly where your DAG is.
-
export the AIRFLOWHOME environment variable
-
initialize the database
-
Schedule the task
-
To open the apache airflow UI in web browser




The web UI looks like following.
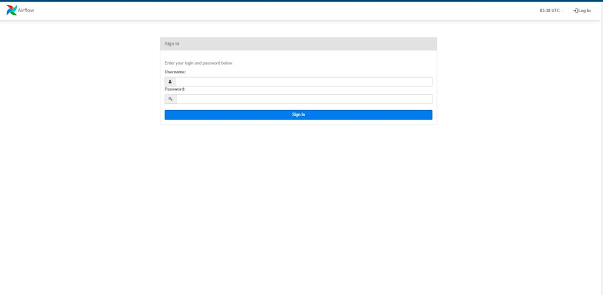
The login username and password is added from terminal with following instruction: In the given instruction, we can specify username, firstname, lastname, password, email and role(viewer,Admin etc).

Once the user is created then we can see following message: Then login with the credentials and we will navigate to homepage. Where we will see our DAG. The homepage has many options to explore.

Code with Description
Python is one of the popular programming language. Using python we can create a data processing pipeline that collects data from the API end point.I have created both API end points as well as DAG . Following libraries and modules have been use


where DAG is used to create a DAG which we will see in further code. As i have mentioned above, PythonOperator is used from airflow.operators.python, datetime and timedelta for date and scheduling interval. BaseModel is imported from the Pydantic library to define data model.Request module is used to fetch data from the API end point.csv module is used to store final data in csv format. Since API is created using Fast API so the shown libraries are used where corsmiddleware is used to resolve cross origin error.
Lets start with how API endpoints are built using Fast API for this project. Here FastAPI
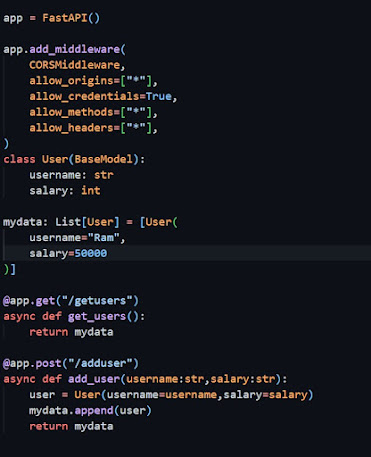
is instantiated and assigned to app. To overcome the cross origin error middle ware is added which allows basically any origin to exchange data and communicate. In this case data is transferred from localhost:5000 to localhost 8000. Next a class of User is made with the data model containing Username and salary with respective datatypes using BaseModel. The List of User is assigned to mydata where list of users according to data model is stored. One example data is also stored. Here two api end points are specified i.e one for get request and one for post request. User data is posted form the API UI. Now with the following command fast api is started (api is name of my python file i.e api.py)
uvicorn api:app –port 5000 –host 0.0.0.0 –reload
**
**
Next lets see the data pipeline for collecting data from the api end point.
Function fetchdata collects data from the endpoint http://localhost:5000/getuser

After taking the response in json format we unpack the dictionary and assign it to my data, finally store the data in csv format. DAG i.e Directed Acyclic Graph is created and assigned the name fetchdatafromapi.
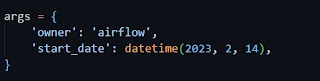
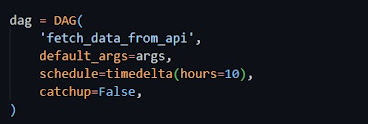
The default argument is assigned with args which contains owner as airflow and start date. Also the DAG is schedule of running once for every 10 hours and start from current date. PythonOperator is used with the taskid fetchdata. The function fetchdata is called
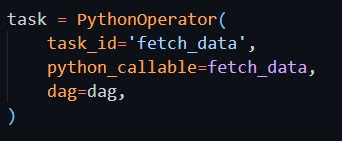
from pythoncallable and the value of dag is assigned.
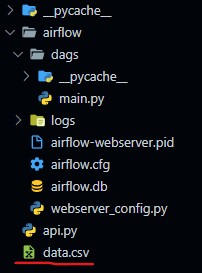
Output
Finally after running the code we will see data.csv in folder structure.
Conclusion
Hence this is simple datapipeline to extract data from the API endpoints. Well depending upon the needs of user many modifications can be made.
Code for Nepal would like to thank DataCamp Donates for providing Prashant, and several other fellows access to DataCamp, to learn and grow.