Building my own IMDB movies dataset using Scrapy
12 Apr 2023 - Shyamron Dongol
Scrapy, a free and open-source web crawling framework, was first release on June 26, 2008 licensed under BSD. It is used for web scraping and extracting structured data. Scrapy is widely used by many employers, for both freelancing and in-house jobs for various applications from data mining to monitoring websites. or changes. Scrapy is popularly used due to its ability to handle requests asynchronously, i.e., it can execute multiple tasks concurrently, such as making requests, processing responses, and saving data. It allows you to focus on the data extraction process utilizing CSS selectors and XPath expressions rather than the complex internals of how spiders are supposed to function. With Scrapy, you can easily build complex scraping pipelines that can handle multiple pages, parse complex HTML structures, and store data in various formats.
Web scraping is a technique for gathering data or information on web pages. Web crawling is usually the first step of data tasks. This blog discusses how powerful scrapy is and how it can be implemented using Python. Movies information such as title, rating, no. of reviews, genres and other information are scraped from imdb.com site. Obtaining this information is the first step towards tasks such as movie recommendation systems, discover trends on movies, visualize how movies’ popularity is dependent on various factors and other visualizations and evaluations.
For example, you can analyze the genres of movies that are currently popular and see how they have changed over time. Furthermore, you can analyze the movie information obtained from Scrapy to see which actors, directors, or production companies are associated with popular movies and use this information to predict the success of future movies.
This blog provides a step-by-step guide on creating a Scrapy project and a spider to scrape data from IMDB. Let’s get going.
Getting Started (Prerequisites)
- Install scrapy.
Firstly, we have to install scrapy. If you are using anaconda, you can use conda to install scrapy such as:
conda install -c conda-forge scrapy
Or using pip as:
pip install scrapy
Creating our scrapy project
Step 1:
To create our scrapy project, run following command in your appropriate directory.
scrapy startproject imdbscrapy
Here, imdbscrapy is the scrapy project name and our scrapy project folder would look like this:
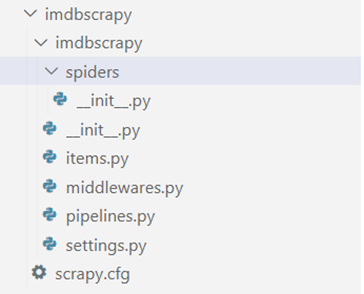
The created project folder contains multiple files each having specific purpose.
Scrapy.cfg — Deploys configuration file.
init.py — Initialization file
Item.py — Project items definition file
Middlewares.py — Project middle wares file
Pipelines.py — Project pipelines file
Setting.py — Project settings file
Spiders/ — A directory where later you will put your spiders.
Spiders are classes that you define and that Scrapy uses to scrape information from websites.
Step 2:
Creating spider: To create a spider, we navigate towards the spider folder and run following command:
scrapy genspider imdb_movies imdb.com
After executing above command, python file named imdb_movies is created in spiders directory with start URL https://www.imdb.com. All the commands will be written here to scrape the information.
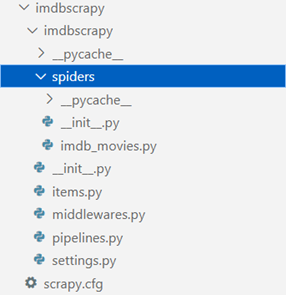
imdb_movies.py would contain python code given as follows.
Step 3:
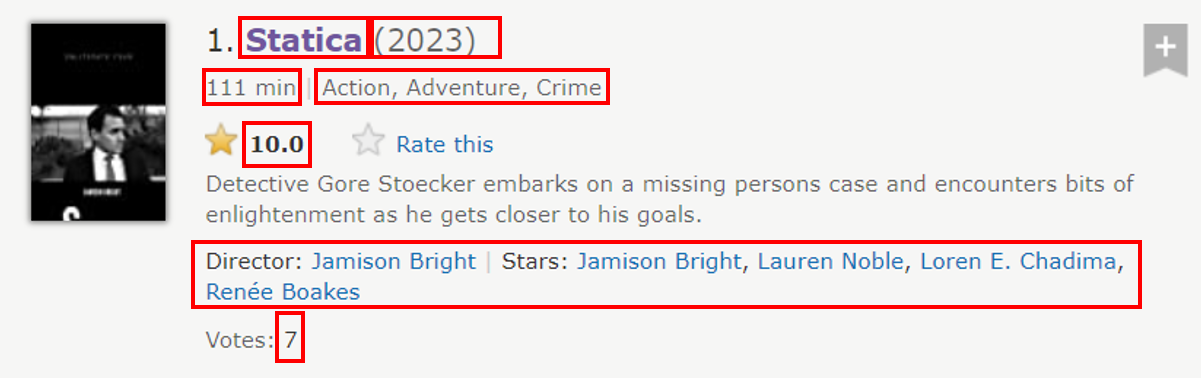
Now, navigating toward Feature Film, Action, English (Sorted by IMDb Rating Descending) — IMDb, i.e., the movies with genre “action” web URL are selected to scrape. It consists of more than 20k+ action movies separated in multiple pages with each page containing maximum 50 movies.
We would want to scrape following features from each action movies:
- Title
- Rating
- No. of reviews
- Directors and Actors
- Genres
- Year
- Runtime
Step 4:
In imdb_movies.py, specify our required urls and genres lists. In this case, since we are only scraping for ‘action’ genre, so genre is a list containing ‘action’. If you want to scrape other genres, you can add it on the list.
Now, yield scrapy request for each url in urls list. In this case there is only one url i.e., for ‘action’ genre.
class ImdbMoviesSpider(scrapy.Spider):
name = 'imdb_movies'
allowed_domains = ['www.imdb.com']
start_urls = 'http://www.imdb.com/'
genres=['action']
def start_requests(self):
urls=[]
for genre in self.genres:\
urls.append(f"{self.start_urls}/search/title/?genres={genre}&languages=en&sort=user_rating,desc&title_type=feature")
for url in urls:
yield scrapy.Request(url=url,callback=self.parse)
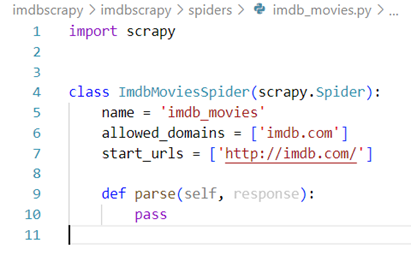
def parse(self, response):
pass
Step 5: ——-
We can use CSS or Xpath to select elements from the websites. First thing to do is navigate towards the required website and right click on the mouse and Inspect. This will display he website’s HTML, CSS, and JavaScript code.
Select Ctrl+ shift + c and click on required elements in the web that you want to extract. This will display the HTML code for the specific feature.

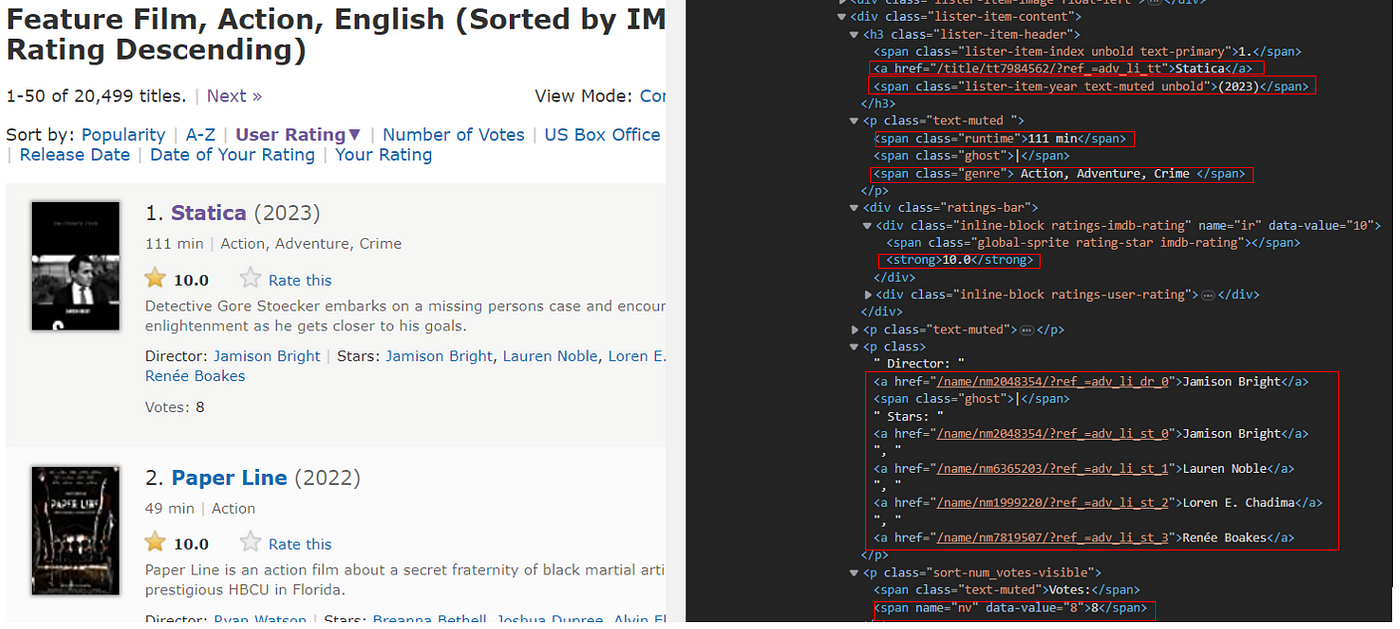
Here, the div class lister-list contains all the movies each separated under div class list-item mode-advanced. Each required items are selected again using span, div or p.
As default, the features variables are set to empty string (‘ ‘) , as all the movies may not have values.
def parse(self, response):
movies_list=response.css('div.lister-list')
for movie in movies_list:
movies=movie.css('div.lister-item.mode-advanced')
year=''
title=''
rating=''
reviews=''
directors_actors=''
genres=''
gross=''
runtime=''
If the div class name is unique then we can directly use the class name. If the same class name is used for other divisions as well, we may want to be specific about which division we want to scrape. Following is the illustration using CSS expression:
for items in movies: rating=items.css(“div.inline-block.ratings-imdb-rating strong::text”).get() runtime=items.css(“span.runtime::text”).get() year=items.css(‘span.lister-item-year.text-muted.unbold::text’).get()
Referencing to figure above, to extract title text, we can use ‘a’ tag, but other divisions also have ‘a’ tag, so we specify the unique division that title ‘a’ tag belong to and then scrape within the division.
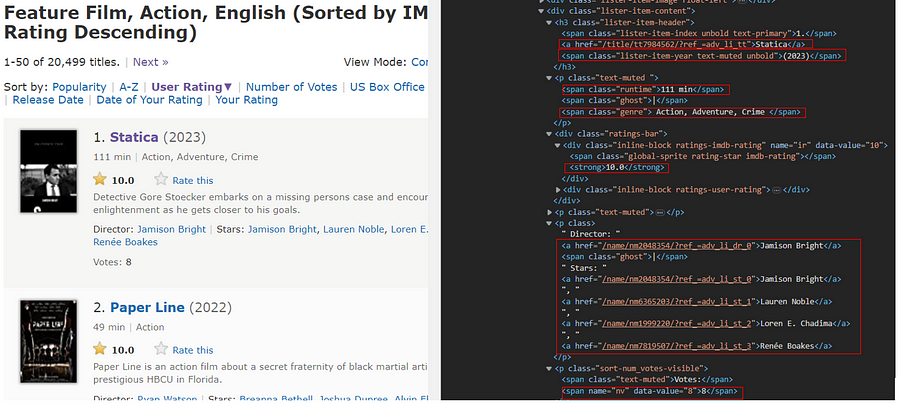{kind=link}
title=items.css(“h3.lister-item-header a::text”).get()
genres=items.css(“p.text-muted span.genre::text”).get()
Syntax:
feature = response.css(“div.parent-class div.child-class::text”).get()
Step 6:
Another way of writing expressions is using nth-child. Code snapshot is:
for item in items.css('p.sort-num_votes-visible'):
reviews=item.css("span:nth-child(2)::text").get()
gross=item.css('span:nth-child(5)::text').get()
In above code, the second and fifth child span within element ‘p’ are being accessed to obtain number of reviews and gross obtained from the movie
Step 7:
We can also use Xpath for extracting elements.
for item in items.css('div.lister-item-content'):
for names in item.xpath('.//p[3]'):
directors_actors = [name.strip() for name in names.css('::text').extract()]
Here, actors and directors’ names are extracted from third ‘p’ element within div class lister-item-content.
| If you want to learn more about detailed information and syntax relating to scrapy Xpath and CSS expressions, refer this tutorial [Scrapy Python: How to Make Web Crawler in Python | DataCamp](https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python) . |
Step 8:
Doing this will extract required elements from one page of website. We can further modify the code to extract from multiple pages.

Code snippet is:
next_page = response.css('a.lister-page-next.next-page').attrib['href']
next_page = f"{self.start_urls}/{next_page}"
print(f"temp:{next_page}")
if next_page is not None:
yield response.follow(next_page,callback=self.parse)
In this code, href is extracted from ‘a’ element to navigate to next page. This code allows the spider to follow links to the next page of search results until there are no more pages.
Step 9:
The spider is run by following command:
scrapy crawl imdb_movies -O movies.csv
A dataset name movies.csv is obtained.
Compiling all the code snippets, complete code for our spider is:
import scrapy\
class ImdbMoviesSpider(scrapy.Spider):
name = 'imdb_movies'
allowed_domains = ['www.imdb.com']
start_urls = 'http://www.imdb.com/'
genres=['action']
def start_requests(self):
urls=[]
for genre in self.genres:
urls.append(f"{self.start_urls}/search/title/?genres={genre}&languages=en&sort=user_rating,desc&title_type=feature")
for url in urls:
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
movies_list=response.css('div.lister-list')
for movie in movies_list:
movies=movie.css('div.lister-item.mode-advanced')
year=''
title=''
rating=''
reviews=''
directors_actors=''
genres=''
gross=''
runtime=''
for items in movies:
rating=items.css("div.inline-block.ratings-imdb-rating strong::text").get()
runtime=items.css("span.runtime::text").get()
year=items.css('span.lister-item-year.text-muted.unbold::text').get()
title=items.css("h3.lister-item-header a::text").get()\
genres=items.css("p.text-muted span.genre::text").get()
for item in items.css('p.sort-num_votes-visible'):
reviews=item.css("span:nth-child(2)::text").get()
gross=item.css('span:nth-child(5)::text').get()
for item in items.css('div.lister-item-content'):
for names in item.xpath('.//p[3]'):
directors_actors = [name.strip() for name in names.css('::text').extract()]
yield{\
"year":year,
"title":title,
'rating':rating,
'no_of_reviews':reviews,
'directors_actors':directors_actors,
'genres':genres.strip(),
'runtime':runtime,
'gross':gross
}
next_page = response.css('a.lister-page-next.next-page').attrib['href']
next_page = f"{self.start_urls}/{next_page}"
print(f"temp:{next_page}")
if next_page is not None:
yield response.follow(next_page,callback=self.parse)
After executing the spider, all 20,464 action movies from IMDB were extracted. The dataset contains a lot of dirty values and empty cells. Data manipulations and data preprocessing can be done before applying the data to proper use. Complete code along with extracted dataset can be found in GitHub here.
Conclusion
By implementing the spider code, 20k+ action movies were scraped in about 15–20 minutes. This clearly show how power scrapy is. You can explore further about scrapy here to scrape your own dataset.
References:
- Scrapy Python: How to Make Web Crawler in Python, DataCamp
- Scrapy Tutorial — Scrapy 2.8.0 documentation
- Using Scrapy to Build your Own Dataset, Experfy Insights
- Web Scraping with Python — DataCamp Learn
Code for Nepal would like to thank DataCamp Donates for providing Shyamron, and several other fellows access to DataCamp, to learn and grow.